dev-resources.site
for different kinds of informations.
Building ETL/ELT Pipelines For Data Engineers.
Introduction:
When it comes to processing data for analytical purposes, ETL (Extraction, Transformation, Load) and ELT (Extract, Load, Transform) pipelines play a pivotal role. In this article, we will delve into the definitions of these two processes, explore their respective use cases, and provide recommendations on which to employ based on different scenarios.
Defining ETL and ELT:
ETL, which stands for Extraction, Transformation, and Load, involves the extraction of data from various sources, transforming it to meet specific requirements, and then loading it into a target destination. On the other hand, ELT, or Extract, Load, Transform, encompasses the extraction of raw data, loading it into a target system, and subsequently transforming it as needed. Both ETL and ELT serve the purpose of preparing data for advanced analytics.
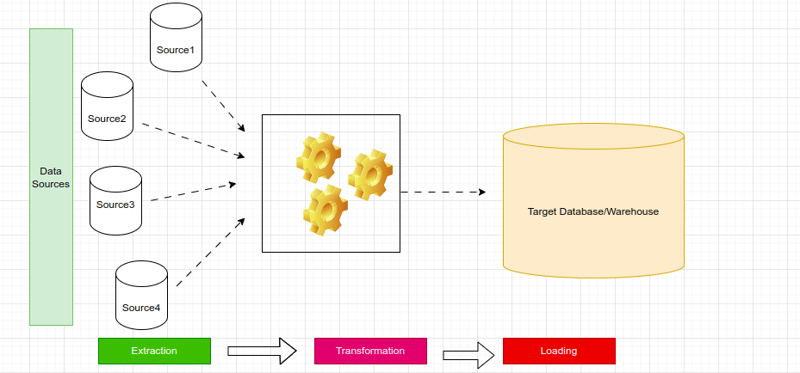
ETL Process Utilization:
ETL pipelines are often used in situations involving legacy systems, where data engineers respond to ad hoc business requests and intricate data transformations. This process ensures that data is refined before being loaded into the target system, enhancing its quality and relevance.
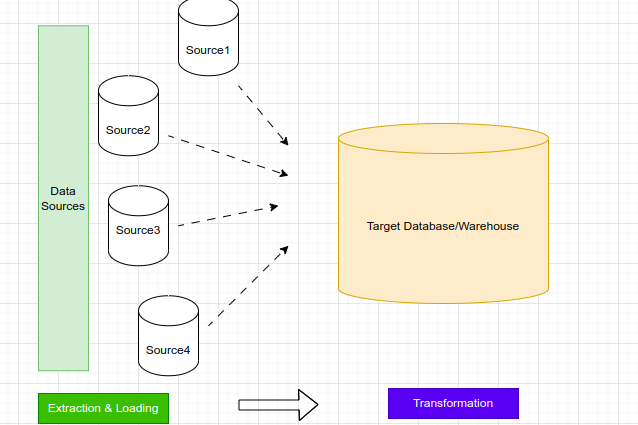
ELT Process Preference:
ELT pipelines have gained preference due to their swifter execution compared to ETL pipelines. Additionally, the setup costs associated with ELT are lower, as analytics teams do not need to be involved from the outset, unlike ETL where their early engagement is required. Furthermore, ELT benefits from heightened security measures within the data warehouse itself, whereas ETL necessitates engineers to layer security measures.
Exploring a Practical ETL Pipeline Project:
To gain hands-on experience in Data Engineering, cloud technologies, and data warehousing, consider working on the project "Build an ETL Pipeline with DBT, Snowflake, and Airflow." This project provides a solid foundation and equips you with valuable skills that stand out in the field. The tools employed in this project are:
- DBT (Data Build Tool) for ETL processing.
- Airflow for orchestration, building upon knowledge from a previous article.
- Snowflake as the data warehouse.
Build an ETL Pipeline with DBT, Snowflake and Airflow
Conclusion
In conclusion, we have gained a comprehensive understanding of ETL and ELT pipelines, including their distinctive use cases. By considering the scenarios outlined here, you can make informed decisions about which approach suits your data processing needs. As a recommendation, engaging in the mentioned project will undoubtedly enhance your expertise in Data Engineering, cloud technologies, and data warehousing. Embark on this journey to stand out and continue your learning in this dynamic field.
Happy learning!
Featured ones: