dev-resources.site
for different kinds of informations.
用 2Captcha 通過 CAPTCHA 人機驗證
往往我們在做爬蟲或 bot 的時候,最難跨過的問題之一大概就是那 CAPTCHA 人機驗證了,有的團隊會選擇自行開發辨識技術來通過 CAPTCHA 人機驗證,然而面對越來越難的人機考驗,例如 Google 的 reCAPTCHA,若真要自行開發,那得付出相當程度的時間與精神,本文要介紹的 2Captcha 是幫助我們通過 CAPTCHA 人機驗證的服務,透過 2Captcha API,讓我們可以方便快速的通過那些 CAPTCHA 考驗,省去大量自行開發的時間與金錢。
在介紹 2Captcha 前,先簡單的認識一下 CAPTCHA。
CAPTCHA
CAPTCHA 全稱是「Completely Automated Public Turing test to tell Computers and Humans Apart」,翻譯成華文是超級繞口的「全自動區分電腦和人類的公開圖靈測試」,這串無敵長的文字簡單講就是人機驗證,CAPTCHA 人機驗證存在的目的通常是為了遏止網站被外部的程式惡意的大量操作,然而這樣的機制也擋住了我們家從事無害工作的可愛小爬蟲 🐛 或小機器人 🤖,所以我輩開發者就需要像 2Captcha 這樣的服務幫我們通過那 CAPTCHA 考驗。
常見的 CAPTCHA
在台灣常見到的 CAPTCHA 的場合大概有這些:
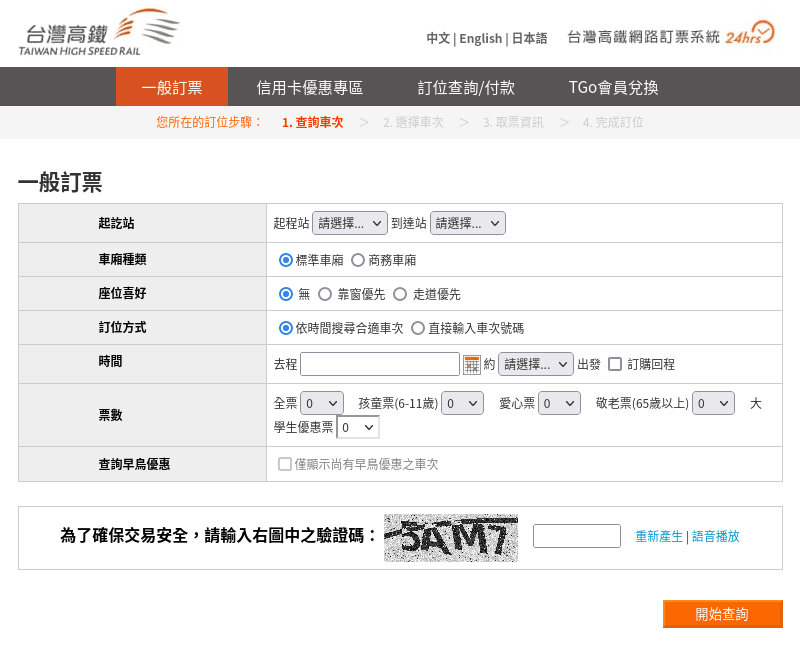
台灣高鐵
台灣高鐵的 CAPTCHA 是較為傳統的文字混淆型:
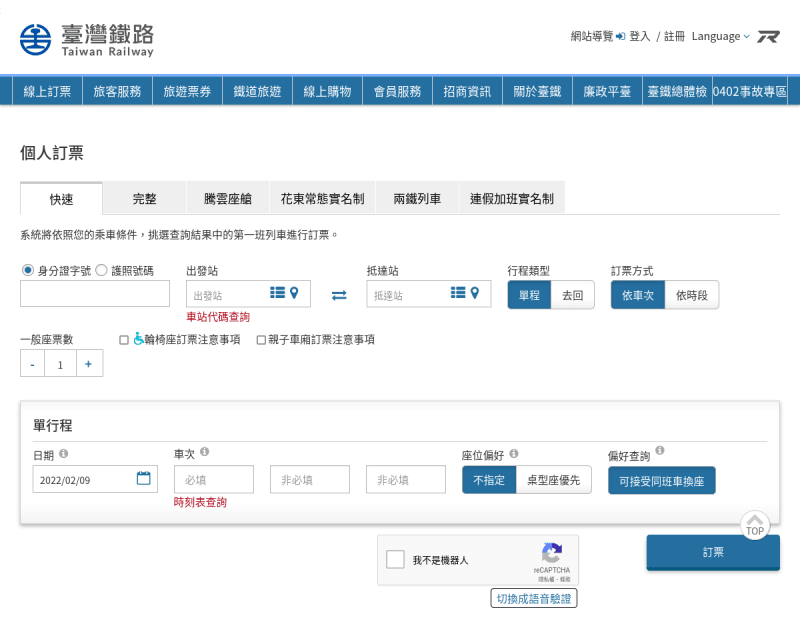
臺灣鐵路
臺鐵的則是用 Google 的 reCAPTCHA:
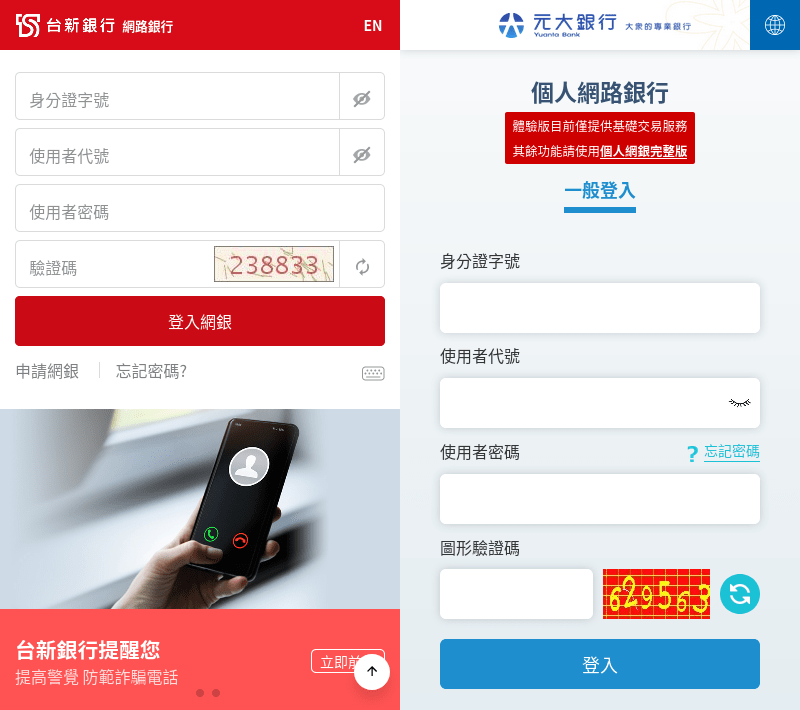
網路銀行
除了訂票外,網銀也很常看到 CAPTCHA:
特別要說明的是,上面的舉例僅是用於說明 CAPTCHA 的使用場景,請不要動搶票的歪腦筋,那有可能是違法的,請諮詢專業法律人士獲得正確的法律知識,也歡迎留言共同討論。
2Captcha

先簡單認識 2Captcha,做為一個辨識 CAPTCHA 的服務,2Captcha 背後的辨識機制其實是由人工完成的,我們傳送給 2Captcha 的圖片,都會轉送給分散在全世界的 2Captcha worker 們,經過人工辨識後再把結果回傳,而那些辛苦的 worker 們也可以透過 2Captcha 的仲介機制獲得報酬,因為是人工辨識,所以我們可以預期:
- 正確率應該是高的,2Captcha 也有自己的品質把關機制,剃除掉不適任的 worker,一般來說正確率在九成以上。
- 應該會有些許的等待時間,才能得到辨識後的結果,在 2Captcha API 文件有提到,一般形式的 CAPTAHA 建議等待 5 秒,而較難的 reCAPTCHA 則建議等待 20 秒。
2Captcha 的收費
在費用方面,2Captcha 是採用動態計價,動態的基準是當前 2Captcha 與 worker 們的工作負荷,當負荷量大時會升價、負荷量小時會降價,當前的費率會顯示在 Statistics 頁面,例如下面是本文撰寫時的費率:

上圖可以看到,普通的 CAPTCHA 每一千個收費僅 0.74 美金,而較難的 reCAPTCHA 每一千個則收費 2.99 美金,相較於自行開發各種花式 AI 辨識系統所要花費的人力物力,2Captcha 算是相當低廉的價格了。
在 Statistics 頁面,除了費率外,還有目前 2Captcha 服務的負載程度,以及解題的速度,上圖顯示一般的 CAPTCHA 花 15 秒,而 reCAPTCHA 要花 46 秒,儘管與 2Captcha 文件內的 5 秒、20 秒有差距,看起來還在可以接受的程度內。
在簡單的認識 2Captcha 的機制與收費之後,下面就來實際玩玩看 2Captcha 吧!
2Captcha 辨識一般 CAPTCHA
在這個範例中,我們會示範用 Playwright 登入一個網站,並且用 2Captcha 協助我們辨識登入時的 CAPTCHA 驗證碼。
事前準備
在開始前簡單的介紹一下 Playwright,Playwright 是微軟開發的瀏覽器自動化套件,類似於陳年的 Selenium,Playwright 的優點有:
- 自帶瀏覽器,包括 Firefox、WebKit、Chromium,Playwright 一行指令就都幫我們配置到好。
- 跨語言,Playwright 有 Node.js、Python、.NET、Java 版本,並且不同的語言有著共通的邏輯與相似的 API。
- 自動等待元素現身,才執行相關敘述,相當大程度的省去了手動調試等待時間的心力。
做為一個瀏覽器自動化工具,當然是最適合拿來開發爬蟲或 bot 了,特別是 client side rendering 當道的現在,很難在不使用真正的瀏覽器的條件下做出爬蟲或bot。
在 2Captcha 方面,開立帳號後,登入可以看到 2Captcha API key:
這組 API key 用於與 2Captcha 程式交互,下面的範例程式中的 API key 是無效的,請務必換成您個人的 API key。
登入與 CAPTCHA 辨識
回到範例的主題上,下面我們會用 Playwright for Python 以及 2Captcha 的 Python 套件,示範通過下面這個登入頁面:
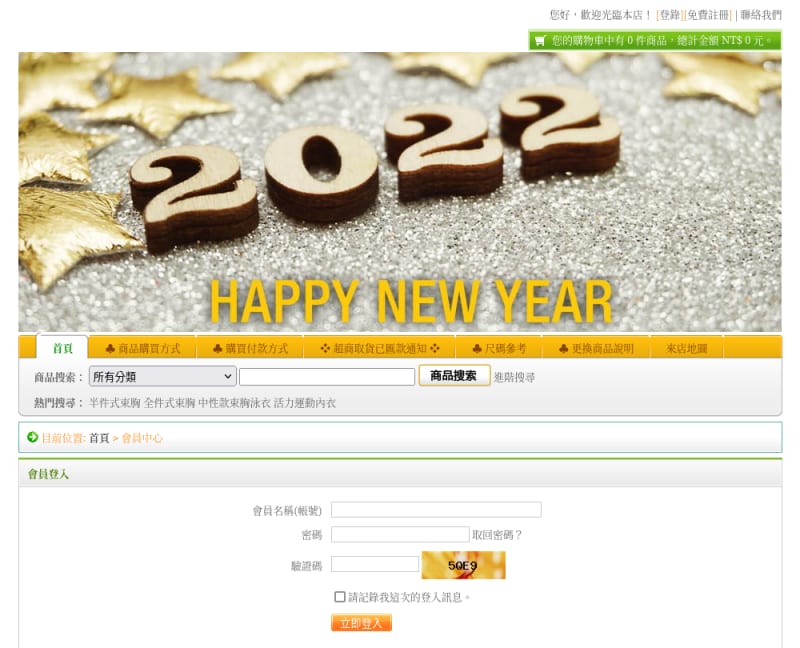
在這個典型的登入表單中,我們的腳本會用 Playwright 輸入帳密,並且把那 CAPTCHA 圖片透過 2Captcha API 取得驗證碼,最後點按「登入」:
import base64
from playwright.sync_api import sync_playwright
from twocaptcha import TwoCaptcha
CAPTCHA_API_KEY = '5c0f7e0306aa2e0398510ef9ce6dbca'
solver = TwoCaptcha(apiKey=CAPTCHA_API_KEY)
def solve(image):
try:
result = solver.normal(
file=image,
numeric=4,
minLength=4,
maxLength=4,
caseSensitive=1
)
except Exception as e:
print(e)
print(result)
return result
def report(captcha_id: str, success: bool):
solver.report(captcha_id, success)
def main():
while True:
with sync_playwright() as p:
browser = p.firefox.launch(headless=False, slow_mo=500)
context = browser.new_context()
page = context.new_page()
page.goto("http://www.twoas.idv.tw/user.php")
page.type("input[name=username]", "RSOB")
page.type("input[name=password]", "RSOBPassword")
screenshot_bytes = page.locator("img[alt=captcha]").screenshot()
captcha_image = base64.b64encode(s=screenshot_bytes).decode('utf-8')
result = solve(image=captcha_image)
page.type("input[name=captcha]", result['code'])
page.click("text=立即登入")
login_message = page.text_content("div.tips")
try:
assert login_message == "登入成功"
except AssertionError as e:
report(result['captchaId'], False)
continue
report(result['captchaId'], True)
page.pause()
context.close()
browser.close()
break
if __name__ == '__main__':
main()
上面的腳本,可以分成 Playwright 操控瀏覽器的部份與 2Captcha 交互的部份。
Playwright 的部份,我們用 page 物件操控大多數的瀏覽器行為,相信即使是對 Playwright 不熟悉的朋友也可以望文生義:
- 用
goto()函式前往指定網址。 - 用
type()函式找到特定元素,並輸入字元。 - 用
locator()函式找到元素並操控它。 - 用
screenshot()函式對元素截圖。 - 用
click()函式點按特定元素。
在用 screenshot() 取得 CAPTCHA 圖片後,用 base64 模組轉換成 Base64 編碼,交給 solve() 函式處理。
在 CAPTCHA 辨識部份,此網站的 CAPTCHA 如下例:
![]()
這是一種相對普通的 CAPTCHA,在 2Captcha 的分類上,屬於 normal 型。
在 2Captcha 的部份,先定義一個 2Captcha 的 solver 物件,並用下面的敘述得到辨識後的文字:
result = solver.normal(
file=image,
numeric=4,
minLength=4,
maxLength=4,
caseSensitive=1
)
因為 CAPTCHA 屬於 normal 型,所以我們調用的是 normal() 函式,函式內的參數,除了 file 是必填,其他都是可選用的:
-
file可接受一個經 Base64 編碼的 CAPTCHA 圖片物件,也可以是本地的圖片檔案,或圖片的 URL。 -
numericCAPTCHA 的字元型態,4表示會有字母與數字,其他的定義請參閱 2Captcha API 文件。 -
minLength最小字元長度,以此例而言,都是固定四個字元。 -
maxLength最大字元長度,以此例而言,都是固定四個字元。 -
caseSensitive設為1表示區分大小寫。
經過上面的交互,取得 result,result 是一個結構如下的 dict 物件:
{'captchaId': '69475003267', 'code': '4QR5'}
其中的 cpatchaId 是 2Captcha API 賦予的交互 ID,而 code 當然就是辨識後的答案啦!
回饋辨識與否
取得 result['code'] 後,填入表單,若正確登入,我們用 report() 回饋成功紀錄給 2Captcha,並在最後的 break 語句完全結束 while 迴圈。
反之若是失敗,則用 report() 回饋失敗紀錄給 2Captcha,並在後續的 continue 語句中斷這次的 while 迴圈,進入下一個 while 迴圈,藉此做出重試的效果。
成果
最後的成果可以參考這個影片:
用 2Captcha 通過 reCAPTCHA
完成前一個較簡單的例子後,我們來玩玩看如何用 2Captcha 通過難一點的 reCAPTCHA,也就是那著名的靈魂考驗「我不是機器人」:

要用 2Captcha 通過 reCAPTCHA 的「我不是機器人」考驗,必須先取得目標頁面的 site key,在原始碼裡面就可以找到這把公開的 site key:
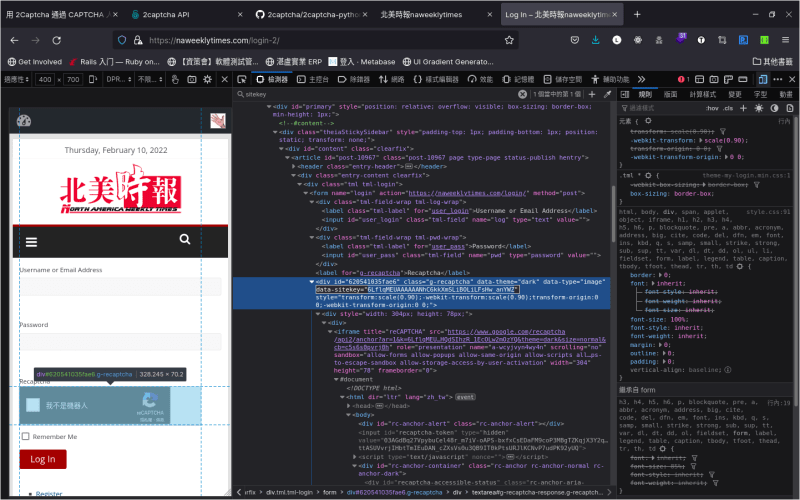
有了 site key 之後,就可以依樣畫葫蘆,呼叫 2Captcha API 得到 reCAPTCHA 的通關密語。
與 2Captcha 交互的部份改成這樣:
result = solver.recaptcha(
sitekey='6LflqMEUAAAAAANhC6kkXmSLiBOLiLFsHw_anYWZ',
url="https://naweeklytimes.com/login-2/",
version="v2",
)
拿到的 result 也是同樣的 dict 結構,只是變成超長的 token:
{'captchaId': '69482081140', 'code': '03AGdBq252s4QsHsrr9CqzkkswdnHsUPLXIcE4OI1pEX4FUP9rNY8p760yLBsd9goaMn61vw95x981lU0...'}
然後我們要把那組 code 填入一個名為 g-recaptcha-response 的文字框,然而這個文字框是隱藏的,所以得先用 Playwright 跑一小段 JS 讓它顯示出來:
page.eval_on_selector(
selector="textarea[name=g-recaptcha-response]",
expression="(el) => el.style.display = 'inline-block'",
)
上面的函式中,JS 的 el 就是來自 selector 抓到的元素。
文字框顯示出來會像這樣:
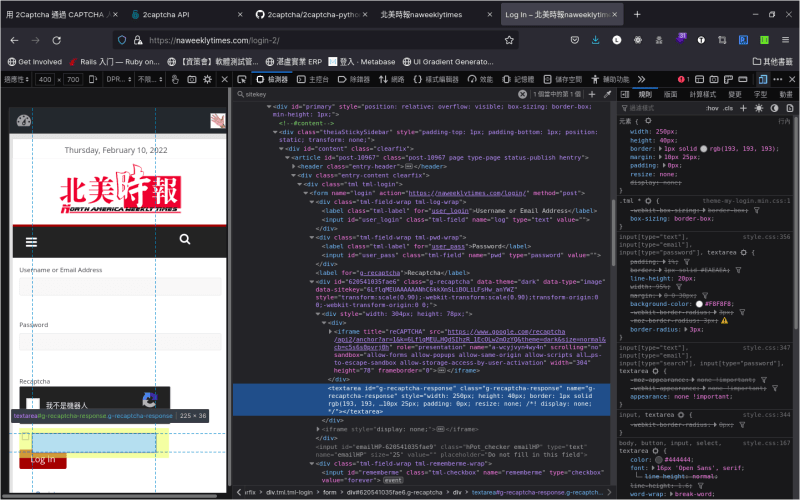
然後就比照第一個範例,帳號、密碼、reCAPTCHA 通關密語填一填,就可以成功登入囉!
成果
完整的程式碼如下:
from playwright.sync_api import sync_playwright
from twocaptcha import TwoCaptcha
URL = "https://naweeklytimes.com/login-2/"
SITEKEY = '6LflqMEUAAAAAANhC6kkXmSLiBOLiLFsHw_anYWZ'
CAPTCHA_API_KEY = '5c0f7e0306aa2e0398510ef9ce6dbca'
solver = TwoCaptcha(apiKey=CAPTCHA_API_KEY)
def solve(url: str):
try:
result = solver.recaptcha(
sitekey=SITEKEY,
url=url,
version="v2",
)
except Exception as e:
print(e)
raise Exception
print(result)
return result
def report(captcha_id: str, success: bool):
solver.report(captcha_id, success)
def main():
while True:
with sync_playwright() as p:
browser = p.firefox.launch(headless=False, slow_mo=500)
context = browser.new_context()
page = context.new_page()
page.goto(URL)
page.type("input[name=log]", "RSOB")
page.type("input[name=pwd]", "RSOBPassword")
try:
result = solve(url=URL)
except Exception as e:
continue
page.eval_on_selector(
selector="textarea[name=g-recaptcha-response]",
expression="(el) => el.style.display = 'inline-block'",
)
textarea = page.locator("textarea[name=g-recaptcha-response]")
textarea.fill(result['code'])
page.click("input[type=submit]")
try:
assert page.url == "https://naweeklytimes.com/"
except AssertionError as e:
report(result['captchaId'], False)
continue
report(result['captchaId'], True)
page.pause()
context.close()
browser.close()
break
if __name__ == '__main__':
main()
看起來有點長,不過和黑科技 AI 相比應該是小巫見大巫。
下面是執行的影片:
結語
本文我們示範用 2Captcha 通過普通的 CAPTCHA 及 reCAPTCHA,在這兩種最常見的 CAPTCHA 外,2Captcha 還支援其他各式各樣的 CAPTCHA,形式眾多,可以參考 2Captcha 的文件與 demo 頁。
在 API 方面,2Captcha 有提供封裝好的 Python、GO、PHP、Java、C#、C++ 套件,即使是沒有現成套件的語言,直接呼叫 2Captcha API 也不是太困難的事。
至於 2Captcha 的費用,除了真的很便宜的費率外,在設計 bot 時,只要保留住登入後的 cookie 或 local storage,即可省下每次都要重新登入的時間以及 CAPTCHA 的費用,以 Playwright 為例,它就有 reuse authentication state 的機制,可以多加利用。
參考資料
- 維基百科〈驗證碼〉
Featured ones: